Зміст:
- 1 Як потрапити до підказок Яндекса
- 1.1 Плюси системи підказок для обивателя:
- 1.2 Плюси для SEO-оптимізаторів:
- 1.3 Правила створення підказок
- 1.4 Властивості контенту
- 1.5 Релевантність, або ступінь відповідності потреб користувача
- 1.6 Популярність
- 1.7 Які підказки видаляються
- 1.8 Способи накрутки підказок
- 1.9 Легальні, «білі» методи формування підказок
- 2 Як ми навчилися передбачати запит користувача та прискорили завантаження пошукової видачі
Як потрапити до підказок Яндекс?
Форма Яндекс Пошуку для сайту показує підказки, як відвідувач сайту набирає запит. Щоб налаштувати пошукові підказки, виберіть потрібний пошук на сторінці Мої пошуки та перейдіть до розділу Пошукові підказки.
Як піднятися у пошуку Яндекса?
Як піднятися вище у результатах пошуку
- Попросіть замовників залишити відгук про вашу роботу. Чим більше у вас позитивних відгуків, тим вища ваша позиція у загальному каталозі виконавців.
- Заповніть профіль максимально повно. …
- Підключіть профіль в особистому кабінеті.
Що таке Яндекс підказки?
Коли користувач починає вводити запит у пошуковому рядку Яндекса, пошуковик показує кілька найбільш популярних запитів, що починаються на вже введені літери., – Це пошукові підказки. Пошукові підказки допомагають заощадити час – можна не друкувати запит повністю.
Пузат.ру
Пошукові підказки Яндекса: що це, навіщо вони потрібні, парсинг онлайн, формування
Як потрапити до підказок Яндекса
На зразок Google, у якої система підказок з'явилася першою, програмісти Яндекса розробили власний алгоритм.
Як працюють пошукові підказки у пошукових системах, знає будь-хто з нас. Маса варіантів ще не закінченої фрази миттєво з'являється нижче за рядок пошуку на Яндексі або Google. Користувачеві залишається лише вибрати потрібний варіант.
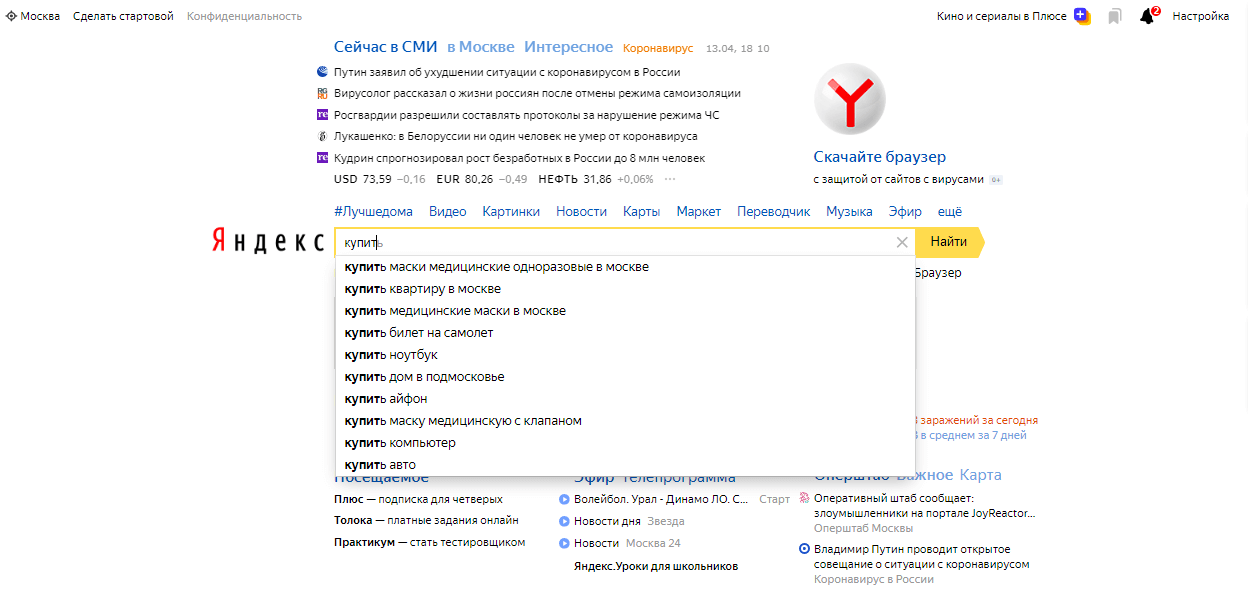
Підказка в Яндексі
Плюси системи підказок для обивателя:
- економія часу;
- автоматичне виправлення помилок у разі неточного набору;
- вміння підлаштовуватися під уподобання споживача: показ назв сайтів, якими найчастіше користуються з пристрою.При цьому в налаштуваннях браузера легко видалити ті, які більше не хочеться бачити.
Втім, позитивні моменти системи підказок активно використовують як прості користувачі ПК, а й веб-майстра. Вони почали використовувати алгоритм просування сайтів.
Плюси для SEO-оптимізаторів:
- попадання назви послуги, що просувається, товару в пошукові запити різко збільшує трафік сайту;
- до бренду, що вилітає під уведенням, у споживачів підвищується лояльність. Майбутні покупці впевнені, що бачать найпопулярніші запити, а отже фірма є найкращою на ринку.
Що потрібно зробити, щоб потрапити до пошукових підказок Яндекса чи Google? Повірте, це не так просто, але при великому бажанні та певних стараннях дуже навіть можливо. А спочатку ознайомимося зі структурою цього сервісу.
Правила створення підказок
При створенні підказки в Яндексі основне значення мають такі аспекти: дані про регіон та мову, персоналізація, фільтри.
Мова та регіон
Очевидно, що підказки у різних мовних регіонах відрізнятимуться. Мова, вказана у налаштуваннях пошуковика, визначає семантику запитів. Крім того, обидва пошукові системи, Google і Яндекс, знаходять найбільш затребувані запити для кожної місцевості і виводять їх під рядок введення. Тому при наборі запиту «купити» у Москві чи Астрахані продовження буде різним.
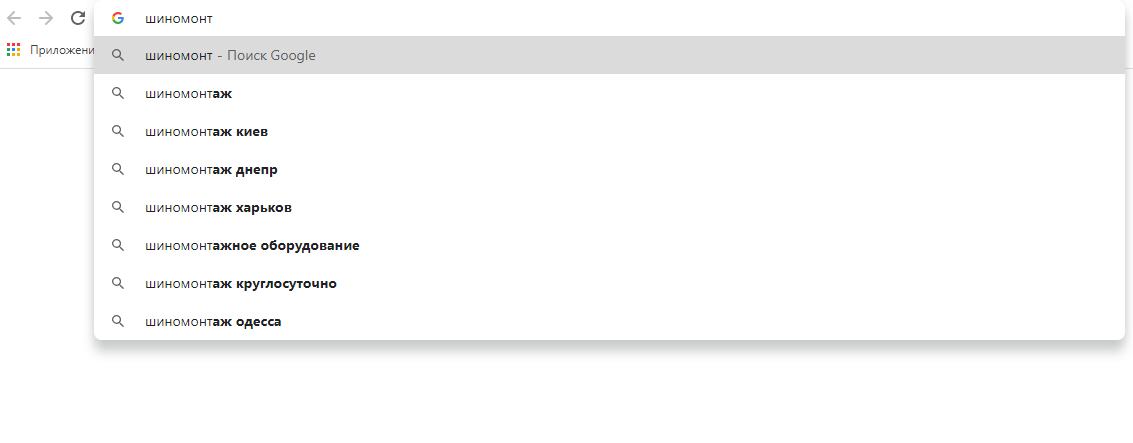
Підказка в Google
Персоналізація
Істотним впливом на формування алгоритму підказок користується використання функцій Web History (Google) і «Мої знахідки» (Яндекс). Найчастіші запити з пристрою виділяються у підказках іншим кольором, сигналізуючи про переваги власника пристрою.
Фільтри
Усі запити користувачів автоматично відфільтровуються системою, видаляється нецензурна лайка, виправляються неточності, відсіваються рідкісні запити. Користувачеві надається вибірка з понад 20 мільйонів запитів, які поділяються на групи з семантики (значення) слів, об'єднуючись у схожі за змістом вирази, наприклад, «друк», «друк на футболках», «друк на гуртках».

Підказки на запит «друк»
Автоматичний алгоритм сортування підказок враховує загальні властивості контенту сайтів, соцмереж, вибір користувача та «свіжість» запиту.
Властивості контенту
У мережі широко відома історія індійського блогера-експериментатора Ріші Сакхані, який сформував два схожі запити у Twitter і попросив своїх фоловерів їх запостити. В результаті фраза Rishi Sakhani ROFL потрапила в підказки Google, а друга Rishi Sakhani ha ha – опинилася в групі пов'язаних запитів, але в підказки не потрапила. Звідси висновок, що пошуковик враховує не лише кількість прямих запитів у пошуковому рядку, а й наскільки часто таке поєднання зустрічається всередині контенту певного сайту.
Релевантність, або ступінь відповідності потреб користувача
Персоналізація запитів відбувається завдяки вмінню браузера зберігати дані про відвідувані сайти. Пошукові системи визначають цінність підказки для кожного власника пристрою, виходячи з особистої історії запитів.
Популярність
"Свіжість" запиту враховується Google, вона пропонує користувачеві звернути увагу на підказки, що мають високу затребуваність у пошуковій системі на даний момент. При падінні інтересу популярне поєднання видаляється.
В Яндексі оновлення підказок проводиться раз на добу, що втрачають цінність автоматично забираються системою.Крім того, в пошуковій системі існують так звані «швидкі підказки», які формуються на підставі численних запитів користувачів кожні півгодини за матеріалами нових статей, конверсії постів у соцмережах і т.д.
Які підказки видаляються
Політика пошукових систем у цьому випадку єдина, із загального потоку за допомогою фільтрів видаляються матеріали, якщо вони:
- містять порнографічні відео та фото;
- закликають до насильства та ненависті;
- за рішенням суду мають бути вилучені.
Способи накрутки підказок
Як уже говорилося вище, включити назву бренду до підказок досить складно. Google і Яндекс борються з сеошниками, формують нові алгоритми ранжування, щоб якнайменше назв фірм, просуваних послуг потрапляло у видачу пошуковиків.
Існує два «чорні» методи формування підказок:
Ручний створюється за допомогою великої кількості користувачів, залучених до популяризації запиту. Згадаймо, як підказав Ріші Сакхані. Зазвичай такий спосіб застосовується, якщо потрібно потрапити до підказок на короткий час. Для веб-майстра за наявності коштів актуальним є звернення на біржі, типу eTXT, «Адвего», де за допомогою найнятих копірайтерів він зможе вводити в рядок пошуку потрібний запит. Спосіб досить дорогий, що вимагає постійної уваги, тому що:
- при виявленні запитів з однакових підказки IP видаляються;
- потрібен постійний підбір нових виконавців, що дорого;
- при спаді активності популярність підказки впаде, і її буде видалено.
Автоматизована атака на пошукові системи ведеться за допомогою наборів IP-адрес, програмних скриптів, проксі-сервера, які дозволять створити імітацію великої кількості унікальних користувачів.Спосіб дешевий, але в рамках просування одиничного бренду неактуальний. Потрібна розробка програмного забезпечення, спеціальне обладнання, є можливість викриття піратського ПЗ фахівцями служби пошуковика.
Перерахованими вище методами можна досягти певних результатів, але й не виключено, що подібна оптимізація інтернет-ресурсу призведе до неприємності. Якщо сайтом займуться співробітники служби боротьби зі спамом, він втратить не тільки підказки, а й позиції у видачі, впавши в хвіст.
Легальні, «білі» методи формування підказок
Грамотна реклама товару чи послуги допомагає досягти популяризації запиту традиційним, безпечним методом. Чіпляючи обивателя, вона викликає інтерес до бренду, назва якого користувач вводить у рядок пошуку, що рухається емоційним поривом. Чим частіше запит з'являється у пошуку, то швидше з'являється підказка з потрібним поєднанням слів.
Способи, що підвищують частоту запиту користувача:
- тизерна реклама, яка гарно представляє проблему (загадку), за відповіддю до якої обиватель піде на сайт, створюючи запит;
- активна медійна позиція: участь фірми у виставках, конференціях, спонсорство. Зрозумілий та помітний логотип неодмінно залучить нових людей, які захочуть дізнатися більше про компанію, звертаючись до пошуку;
- використання потенціалу відомих інтернет-блогерів, які можуть активно явно чи неявно просувати товар чи послугу.
Як ми навчилися передбачати запит користувача та прискорили завантаження пошукової видачі
Пошукові підказки (саджест) — це не тільки сервіс користувача, але ще й дуже потужна мовна модель, що зберігає мільярди пошукових запитів, що підтримує нечіткий пошук, персоналізацію та багато іншого.Ми навчилися використовувати саджест для того, щоб передбачати підсумковий запит користувача та завантажувати пошукову видачу до натискання кнопки «Знайти».
Впровадження цієї технології – пререндера – вимагало багатьох цікавих рішень у мобільній розробці, розробці пошукового рантайму, логів, метрик. І, звичайно, нам потрібен був крутий класифікатор, що визначає, чи потрібно завантажувати пошуковий запит заздалегідь: цей класифікатор повинен дотримуватися балансу між прискоренням завантаження, додатковим трафіком та навантаженням на Пошук. Сьогодні я розповім про те, як нам удалося створити такий класифікатор.

1. Чи спрацює ідея?
У дослідженнях рідко заздалегідь буває очевидно, що хороше рішення існує. І в нашому випадку ми теж спочатку не знали, які дані потрібні для того, щоб побудувати досить хороший класифікатор. У такій ситуації корисно розпочати з кількох дуже простих моделей, які дозволять оцінити потенційну користь від розробки.
Найпростішою ідеєю виявилася така: завантажуватимемо видачу за першою підказкою з пошукового саджесту; коли підказка змінюється, ми викидаємо попереднє завантаження та починаємо завантажувати вже нового кандидата. Виявилося, що такий алгоритм працює непогано і майже всі запити вдається передзавантажити, проте відповідно зростає навантаження на пошукові бекенди і відповідно зростає трафік користувача. Зрозуміло, що таке рішення впровадити не вдасться.
Наступна ідея теж була досить простою: необхідно завантажувати ймовірні пошукові підказки не у всіх випадках, а лише тоді, коли ми достатньо впевнені, що вони і справді потрібні.Найпростішим рішенням буде класифікатор, який працює прямо в рантаймі за тими даними, які і так є у саджесту.
Перший класифікатор був збудований з використанням всього десяти факторів. Ці фактори залежали від розподілу ймовірностей за безліччю підказок (ідея: чим більше «вага» першої підказки, тим більш ймовірно, що саме вона і буде введена) і довжини введення (ідея: чим менше літер залишилося ввести користувачеві, тим безпечніше завантажувати видачу). Краса цього класифікатора була ще й у тому, що для його побудови не потрібно було нічого релізувати. Потрібні фактори для кандидата можна зібрати, зробивши один http-запит у саджестовий демон, а таргети будуються за найпростішими логами: кандидат вважається «хорошим», якщо підсумковий запит користувача повністю з ним збігається. Зібрати такий пул, навчити кілька логістичних регресій та побудувати діаграму розсіювання виявилося можливим буквально за кілька годин.
Метрики для пререндера влаштовані не зовсім так, як у звичайній бінарній класифікації. Важливими є лише два параметри, але це не точність і не повнота.
Нехай – загальна кількість запитів, – загальна кількість усіх пререндерів, – загальна кількість вдалих пререндерів, тобто. таких, які в результаті збіглися з введенням користувача. Тоді дві цікаві характеристики обчислюються так:
Скажімо, якщо відбувається рівно один пререндер на один запит, а успішними виявляється половина пререндерів, то ефективність пререндера становитиме 50%, і це означає, що вдалося прискорити завантаження половини запитів.При цьому для тих запитів, у яких пререндер спрацював успішно, додатковий трафік не було створено; для тих запитів, у яких пререндер спрацював неуспішно, довелося поставити один додатковий запит; так що загальна кількість запитів у півтора рази більша від вихідного, «зайвих» запитів 50% від вихідної кількості, тому .
У цих координатах я намалював перший scatter plot. Він виглядав так:

Ці значення містили неабияку кількість припущень, але принаймні вже було зрозуміло, що, швидше за все, хороший класифікатор вдасться: прискорювати завантаження для кількох десятків відсотків запитів, збільшуючи навантаження на кілька десятків відсотків — цікавий розмін.
Цікаво було спостерігати, як спрацьовує класифікатор. Дійсно, виявилося, що дуже сильним фактором є довжина запиту: якщо користувач вже майже ввів першу підказку, і вона досить ймовірна, можна здійснити префетч. Так що прогноз класифікатора різко зростає до кінця запиту.
margin prefix candidate -180.424 м майл -96.096 мос мос ру -67.425 мос мос ру -198.641 моск московський час -138.851 моско московський час -123.803 москов московський час -109.841 московс моск85 ська московська олімпіада школярів -135.725 московська московська олімпіада школярів -125.448 московська московська олімпіада школярів -58.615 московська о московська олімпіада школярів 31.414 московська об московська область -66.754 московська область московська область карта 1.716 московПререндер буде корисним, навіть якщо він стався в момент введення останньої літери запиту.Справа в тому, що користувачі витрачають деякий час на те, щоб натиснути на кнопку «Знайти» після введення запиту. Цей час також можна заощадити.
2. Перше використання
Через деякий час вдалося зібрати повністю працюючу конструкцію: додаток ходив за пошуковими підказками в демон саджесту. Той надсилав, серед іншого, інформацію про те, чи потрібно завантажувати першу підказку. Додаток, отримавши відповідний прапор, скачував видачу і, якщо введення користувача в результаті збігалося з кандидатом, здійснювало рендеринг видачі.
Класифікатор на цей момент обзавівся новими чинниками, а моделлю була вже не логістична регресія, а цілком собі CatBoost. Спочатку ми викотили досить консервативні пороги для класифікатора, проте навіть дозволили миттєво завантажувати майже 10% пошукових видач. То справді був дуже зручний реліз, т.к. нам вдалося значно змістити молодші кванти швидкості завантаження видачі, а користувачі помітили це і почали статистично значуще повертатися в пошук: суттєве прискорення роботи пошуку позначилося на тому, як часто користувачі здійснюють пошукові сесії!
3. Подальші покращення
Хоча використання і виявилося вдалим, рішення було все ще вкрай недосконалим. Уважне вивчення логів спрацьовувань показало, що є кілька проблем.
- Класифікатор нестабільний. Наприклад, може виявитися, що з префіксу «янд» він передбачає запит «яндекс», за префіксом «янде» не прогнозує нічого, а, по префіксу «яндек» він знову передбачає запит «яндекс». Тоді наша перша прямолінійна реалізація робить два запити, хоча могла обійтися і одним.
- Пререндер не вміє опрацьовувати послівні підказки.Клік за послівною підказкою призводить до появи додаткового пробілу. Наприклад, якщо користувач ввів "яндекс", його першою підказкою буде запит "яндекс"; але якщо користувач скористався послівною підказкою, введенням буде рядок «яндекс», а першою підказкою — «яндекс карти». Це призведе до плачевних наслідків: вже завантажений запит "яндекс" буде викинутий, замість нього завантажиться запит "яндекс карти". Після цього користувач натисне кнопку «Знайти» і… чекатиме повного завантаження видачі на запит «яндекс».
- У деяких випадках кандидати не мають жодних шансів стати успішними. У саджесті працює пошук по неточному збігу, так що кандидат може, наприклад, містити лише одне слово із введених користувачем; або користувач може зробити друкарську помилку, і тоді перша підказка ніколи не збігається в точності з його введенням.
Звичайно, залишати пререндер із такими недосконалостями було прикро, хай навіть він і корисний. Особливо мені було прикро за проблему з послівними підказками. Я вважаю впровадження послівних підказок у мобільному пошуку Яндекса одним із найкращих своїх впроваджень за весь час роботи в компанії, а тут пререндер не вміє з ними працювати! Ганьба, не інакше.
Насамперед ми виправили проблему нестабільності класифікатора. Рішення обрали дуже просте: навіть якщо класифікатор повернув негативне передбачення, ми не припиняємо завантаження попереднього кандидата. Це допомагає заощаджувати додаткові запити, оскільки коли цей же кандидат повернеться наступного разу, не потрібно буде завантажувати відповідну видачу заново.У той самий час, це дозволяє завантажувати видачі швидше, оскільки кандидат скачується тоді, коли класифікатор вперше спрацював йому.
Потім настала черга послівних підказок. Саджестовий сервер є stateless-демоном, тому в ньому важко реалізувати логіку, пов'язану з обробкою попереднього кандидата для того ж користувача. Здійснювати пошук підказок одночасно для запиту користувача та для запиту користувача без кінцевої пробілу означає фактично подвоїти RPS на демон саджестовий, так що це теж не було хорошим варіантом. У результаті ми зробили так: клієнт передає спеціальним параметром текст кандидата, який завантажується зараз; якщо цей кандидат з точністю до пробілів схожий на введення користувача, ми віддаємо його, навіть якщо кандидат для поточного введення змінився.
Після цього релізу стало можна вводити запити за допомогою послівних підказок і насолоджуватися префетчем! Досить забавно, що до цього релізу префетчем користувалися лише користувачі, що закінчували введення свого запиту за допомогою клавіатури, без саджесту.
Нарешті, з третьою проблемою ми розібралися за допомогою ML: додали факторів про джерела підказок, збіг з введенням користувача; крім того, завдяки першому запуску ми змогли зібрати більше статистики і навчитися за місячними даними.
4. Що в результаті
Кожен із цих релізів давав зростання кількості миттєво завантажуваних видач на десятки відсотків. Найприємніше в тому, що нам вдалося покращити показники пререндера більш ніж удвічі, практично не чіпаючи частину про machine learning, а лише покращуючи фізику процесу.Це важливий урок: найчастіше якість класифікатора не є найвужчим місцем у продукті, зате його покращення є найцікавішим завданням і тому розробка відволікається саме на нього.
На жаль, миттєво завантажені видачі – це ще не повний успіх; завантажену видачу потрібно ще відрендеритищо відбувається не миттєво. Тож ми ще маємо працювати над тим, щоб краще конвертувати миттєві завантаження даних у миттєві відтворення пошукових видач.
На щастя, зроблені впровадження вже дозволяють говорити про пререндера як про досить стабільну фічу; ми додатково перевірили впровадження, описані в пункті 2: вони всі разом також призводять до того, що користувачі самі по собі починають частіше здійснювати пошукові сесії. Звідси ще один корисний урок: значні поліпшення швидкості роботи сервісу можуть статистично значуще впливати на його retention.
На відео нижче можна переглянути, як зараз працює пререндер на моєму телефоні.